TL, DR
Sometimes you may have a list in a Pandas DataFrame column and you are looking to get individual dummy columns for further elaborations. Here a very short guide about how to convert a list to individual dummies.
From list to dummies
In many cases during data exploration and wrangling you will find that you have a list of elements inside a Pandas DataFrame column. For instance, you have a column with the grapes blend used in certain wines like this:

For further analysis you want to convert this list in a series of dummies. But simple list splitting may not work, as the grapes may be in different order and each blend may have different lengths.
Luckily in the Python ecosystem you find plenty of tools for data wrangling. In this case, one of the easiest and most straightforward tool is the MultiLabelBinarizer from scikit-learn.
Let’s see how can we make use of it. I will first provide you the full code, and then I will discuss the main blocks.
import pandas as pd
from sklearn.preprocessing import MultiLabelBinarizer
data_df = pd.DataFrame(
{'grapes':
[['Sangiovese','Merlot','Cabernet Franc'],
['Sangiovese'],
['Merlot','Cabernet Franc','Cabernet Sauvignon'],
['Merlot','Shiraz'],
['Sangiovese','Cerasuolo']]
}, columns=['grapes'])
mlb = MultiLabelBinarizer()
binarized_df = pd.DataFrame(
mlb.fit_transform(data_df["grapes"]),
columns=mlb.classes_,
index=data_df.index)
The result from the above code is the following. You can see that our Pandas DataFrame column list has been converted to dummies:
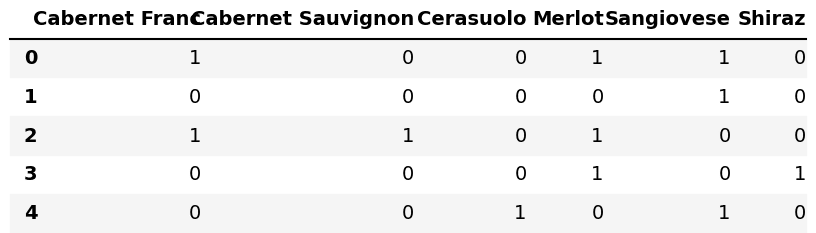
Now let’s look at the various passages. Here we import the necessary packages:
import pandas as pd
from sklearn.preprocessing import MultiLabelBinarizerHere we create our Pandas DataFrame (you may have it from other sources):
data_df = pd.DataFrame(
{'grapes':
[['Sangiovese','Merlot','Cabernet Franc'],
['Sangiovese'],
['Merlot','Cabernet Franc','Cabernet Sauvignon'],
['Merlot','Shiraz'],
['Sangiovese','Cerasuolo']]
}, columns=['grapes'])This line create an instance of the MultiLabelBinarizer:
mlb = MultiLabelBinarizer()Finally, we fit the MultiLabelBinarizer on our column with the list and create a new DataFrame:
binarized_df = pd.DataFrame(
mlb.fit_transform(data_df["grapes"]),
columns=mlb.classes_,
index=data_df.index)And that’s it! Hope you found this guide useful. BTW, I created the images on this pages using the dataframe-image package, you can find a complete guide here.
Related links
Do you like our content? Check more of our posts in our blog!